
Artificial intelligence (AI) adoption is at a tipping point, as more and more organizations develop their AI strategies for implementing the revolutionary technology within their organizations. However, there are still major challenges to AI adoption; in fact, cost of the solution and lack of skilled resources are cited as the top inhibitors of adopting AI.
Even as the technology landscape has experienced massive change and disruption, the way organizations pay for technologies has not kept pace. The traditional pricing model is based on a perpetual licensing model where the business had to estimate what technology and how much of it was needed — usually for the next three to five years. Once decided, the organization would purchase the capacity and pay upfront. However, there is a big problem with this model – if the estimate was wrong, the organization would end up wasting money on under-used or unused technology, leading to disconnect between the cost of the technology and the actual business value.
Many SaaS and cloud-based technologies first disrupted this pricing model by introducing the cloud-based subscription model. With no need for hardware or software installation in their datacenters, and a flexible subscription that allowed for fluctuations in need, this move towards consumption-based pricing disrupted how organizations evaluated and purchased information technology. AI suppliers will need to follow this lead and move towards even more granular pricing that favors transaction-based models to help their clients overcome the cost hurdle of implementing AI solutions.
The AI Stack Build Influences the AI Pricing Model
AI covers a wide range of applications, including natural language processing, machine learning, image/video analytics, and deep learning, among others. While organizations have to choose whether to buy off-the-shelf AI, build their own AI solutions on-premises, or outsource the AI build, there are three main approaches organizations take when building out their AI capabilities: use off-the-shelf, train a model, or integrate a pre-made model that will need inferencing (AI- and ML-driven predictions executed at the edge after having been trained in the cloud, where data storage and processing power are plentiful and scalable) to work within the organization.
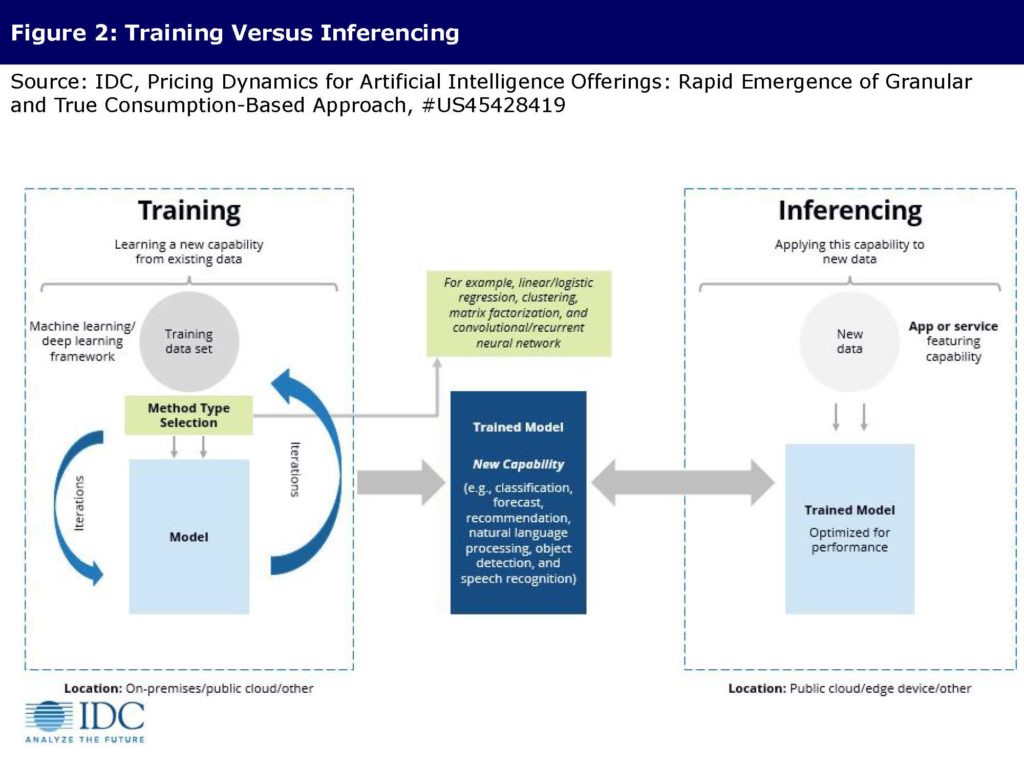
- An organization decides to use an off-the-shelf embedded AI solution for one of its business initiatives, whether it is running on-premises, on public cloud, or at the edge location.
Vendors typically do not charge any premium for the embedded AI services; this pricing reflects how standard the market expects embedded AI capabilities to become. - An organization decides to train a model. There are 4 separate ways that this model can be trained:
- Build and training of the model are done on-premises.The commercially available AI software platforms deployed on-premises is typically priced on a per-seat basis with an annual software license based on the number of individual users who have access to a digital service or product. Vendors who offer perpetual licensing for on-premises AI software platforms usually do it due to the legacy offering and approach and should move to a subscription pricing model.Organizations who choose to train a model on-premises will need underlying infrastructure to support the platform. To accelerate time to value, some leading AI technology vendors are offering an AI-optimized hardware and software bundled solution. The pricing approach for these optimized solutions is evolving to be annual subscription based.
- Build and training of the model are done on public cloud.Here, data scientists have the option to either launch virtual instances with popular deep learning frameworks and interfaces to train sophisticated, custom AI models, or use commercial AI software platforms available as a service.When using commercially available AI software platform as a service, one only pays for what one uses. Building, training, and deploying ML models are typically billed by the second with a one-minute minimum, with no minimum fees, and no up-front commitments.However, when using preconfigured environments, hours of training are typically multiplied by various forms of units of capacity to reflect the compute power or the underlying virtual machine instance subject to the kind of instance selected. Choosing acceleration chips adds another cost on top of the base price.
- Build and training of the model are outsourced to a domain services provider.This training creates a partnership between the customer and the domain services provider. The domain services provider takes the lead on AI model build and training, and the customer provides their custom/proprietary data sets and business processes information to fine-tune the model.The pricing dynamics in this scenario is custom on an engagement-by-engagement basis.
- A pretrained model is available as a public cloud service. An organization’s proprietary data is uploaded to the public cloud and is used to tune or customize a pretrained model.Here, a pretrained model is available as a public cloud service. An organization’s proprietary data is uploaded to the public cloud and is used to tune the pretrained model and then deployed as an API for integration with an application for runtime inferencing. The pricing specifics for this scenario are interdependent with those of using a pretrained, public cloud model deployed as an API for Inferencing (3.2, described below).
- An organization integrates an off-the-shelf pretrained model or a tuned model to an application.
The inferencing needed for this integration can happen in one of three ways:- A pretrained model is available as a public cloud service and invoked on-demand for real-time inferencing.Here, the pretrained model or AI applications is available as a public cloud service and invoked on-demand for real-time inferencing.Organizations pay only for what they use, with no minimum fees or mandatory service usage. For some of the API choices, such as video search, image categorization, or text to speech, payment is done in allotments of pennies or dollars per minute of video, or thousands of images, or thousands of characters of text, based on how frequent API requests are sent to perform inference.Some technology vendors have their AI applications included with the unlimited version of their core application bundle, but for other cloud SKUs, there’s an extra monthly charge that increases depending on the units of millions of predictions you ask of the software.Some leading AI marketing cloud vendors do subscription-based licensing and charge a flat fee for three years, leading to the benefit that the more decisions/recommendations/predictions the client makes and the more they use the AI-powered software, the better pricing they have.
- A pretrained model available as a public cloud service is tuned with proprietary data and then the capability is deployed as an API for Inferencing.The pretrained model is available here as a public cloud service where an organization’s proprietary data is uploaded to the public cloud and is used to tune a pretrained model, create a custom model, and then deploy the capability as an API for inferencing.This scenario pricing also covers training pricing referenced above in scenario 2.4. While organizations pay only for what they use with no minimum fees and no up-front commitments, there are three additional types of costs associated in this type of training-inferencing combination:
- Training hours: Cost for each hour of training required for a custom model based on data provided by customers.
- Data storage: Cost for each unit of data capacity stored and used to train customer’s models.
- A pretrained model is stored in a DevOps-style repository for edge inferencing.This inference style is extremely new, and there is a lack of resources at the edge. However, suppliers have begun introducing technologies, platforms, and devices that can cost effectively extend AI and ML capabilities to the edge of the network. Working in concert with public cloud services, these devices are capable of processing large volumes of data locally and enabling highly localized and timely inference.Organizations pay only for what they use, with no minimum fees or mandatory service usage. For some of the API choices, such as video search, image categorization, or text to speech, payment is done in allotments of pennies or dollars per minute of video, or thousands of images, or thousands of characters of text, based on how frequent API requests are sent to perform inference.
How AI Suppliers Can Help Clients with AI Costs
Cost is one of the biggest inhibitors to enterprise AI adoption. Suppliers can empower their clients to overcome this hurdle by offering granular, consumption-based pricing and flexible licensing for all AI offerings, from core technologies, applications, APIs, or services.
For on-premises build and training of AI models as well as for edge inferencing, technology providers should provide AI-optimized hardware/software bundled solution. This should help ease the complexities of provisioning and management and keep the overall costs in check. Additionally, AI offerings on public cloud should automatically terminate the instances after the jobs are completed, and the billing should be done only for the running time of the jobs.
Consumption-based pricing empowers clients to pay for what they need, lowering inhibitions and fueling AI adoption.
Learn more about AI pricing models in IDC’s Market Perspective: Pricing Dynamics for Artificial Intelligence Offerings: Rapid Emergence of Granular and True Consumption-Based Approach.
Organizations with disruptive AI capabilities and maturity are reaping multiple benefits. Watch IDC’s webcast to hear how some of these innovative businesses are taking advantage of AI – and what they look for in an AI partner.



