
At GTC 2025, NVIDIA introduced several new AI and computing solutions aimed at advancing workstation graphics and AI infrastructure. The RTX PRO Blackwell series brings updated workstation GPUs based on the Blackwell architecture, designed to enhance performance for professional workflows. NVIDIA also unveiled the DGX Spark and DGX Station, expanding AI computing capabilities with Grace Blackwell technology. Additionally, the company highlighted its ongoing ISV collaboration and application optimization efforts, aiming to improve software integration and performance across various AI-driven applications. These updates reflect NVIDIA’s continued focus on developing solutions that support AI and high-performance computing advancements.
NVIDIA Blackwell RTX Pro
The NVIDIA RTX PRO Blackwell series are a new generation of workstation and server GPUs designed to advance workflows for AI, technical, creative, engineering, and design professionals. These GPUs should offer significant improvements in accelerated computing, AI inference, ray tracing, and neural rendering technologies, according to NVIDIA. The RTX PRO Blackwell series include data center GPUs, desktop GPUs, and laptop GPUs, providing professionals with powerful tools for tasks such as agentic AI, simulation, extended reality, 3D design, and complex visual effects.

The RTX PRO Blackwell GPUs feature notable generational enhancements, including up to 1.5x faster throughput with new neural shaders, up to 2x the performance of previous RT Cores, and up to 4,000 AI trillion operations per second with fifth-generation Tensor Cores. They also offer larger, faster GDDR7 memory, enhanced video encoding and decoding capabilities, and support for fifth-generation PCIe and DisplayPort 2.1. These GPUs are designed to elevate productivity, performance, and speed for professionals across various industries, from healthcare and manufacturing to media and entertainment.
DGX Spark: Compact AI Supercomputer for Local and Cloud Integration
NVIDIA has introduced the DGX Spark, a highly compact desktop PC described as AI supercomputer tailored for developers, researchers, and students. This system is powered by the GB10 Grace Blackwell Superchip, which delivers up to 1,000 trillion operations per second (TOPS) of AI computing at FP4 precision. The architecture incorporates fifth-generation Tensor Cores, enabling efficient fine-tuning and inference of large-scale AI models. The DGX Spark is equipped with 128GB of unified LPDDR5x system memory, offering a bandwidth of 273 GB/s through a 256-bit memory interface.

A key feature of the DGX Spark is its use of NVLink-C2C technology, which facilitates coherent memory sharing between the CPU and GPU, achieving bandwidth five times greater than traditional PCIe systems. This capability is particularly beneficial for memory-intensive workloads. The system supports AI models with up to 200 billion parameters locally and can scale further by connecting two units to handle models with up to 405 billion parameters. Additionally, the DGX Spark integrates seamlessly with cloud platforms, including NVIDIA DGX Cloud, allowing users to transition between local and cloud-based AI workflows without significant modifications.
The DGX Spark is designed to empower users with advanced AI capabilities in a desktop form factor, making it suitable for prototyping, fine-tuning, and inferencing tasks across various domains.
DGX Station: High-Performance AI Computing for Desktop Environments
NVIDIA also announced the DGX Station, a continuation in advancement in desktop AI computing, offering data-center-level performance in a workstation format. It is built around the GB300 Grace Blackwell Ultra Desktop Superchip, which combines the Grace 72 CPU cores with a Blackwell GPU, connected via NVLink-C2C interconnect technology. This design enables high-bandwidth coherent data transfers between the CPU and GPU, optimizing performance for large-scale AI training and inferencing tasks.

The system features 784GB of coherent memory, divided between 288GB for the GPU and 496GB for the CPU, making it capable of handling complex AI models and datasets. Networking capabilities are enhanced by the ConnectX-8 SuperNIC, which supports speeds of up to 800Gb/s, allowing for efficient data movement and the ability to link multiple DGX Station units for distributed workloads.
| Feature | Latest GB300 DGX Station | Previous Gen. DGX Station A100 |
|---|---|---|
| Platform / Architecture | NVIDIA Grace Blackwell Ultra Desktop Superchip (GB300) – an integrated solution pairing a custom NVIDIA Grace CPU with an NVIDIA Blackwell Ultra GPU | DGX Station A100 – built on a proven data-center-class design utilizing discrete components |
| CPU | NVIDIA Grace CPU (custom ARM-based processor integrated into the superchip; optimized for AI workloads) | 1 × AMD 7742 (64 cores, 2.25 GHz base / up to 3.4 GHz boost) |
| GPU | NVIDIA Blackwell Ultra GPU – equipped with fifth-generation Tensor Cores offering next-generation FP4 (4-bit floating point) support | 4 × NVIDIA A100 GPUs, each with 80 GB – based on the Ampere architecture and proven for large-scale deep learning workloads |
| GPU Memory/Unified Memory | Up to 784 GB of large coherent (unified) memory – a shared pool combining high-bandwidth on-package memory for both the integrated CPU and GPU | 320 GB total GPU memory (80 GB per GPU) alongside 512 GB of separate DDR4 system memory |
| Interconnect | NVIDIA NVLink-C2C chip-to-chip interconnect – enabling high-bandwidth, coherent data transfers between the integrated CPU and GPU components | Standard NVLink interconnect architecture used to efficiently link the four discrete A100 GPUs (though not the next-gen NVLink-C2C seen in Blackwell) |
| Networking | NVIDIA ConnectX-8 SuperNIC – supports up to 800 Gb/s for high-speed connectivity and scalability for AI clusters | Dual 10GBASE-T (RJ45) networking – sufficient for desktop AI workloads and common office networking needs |
| Storage | Not explicitly detailed in current public disclosures (likely to feature high-speed NVMe storage to complement the onboard AI processing capabilities) | Dual-drive setup: 7.68 TB NVMe U.2 drive for data storage plus a separate Boot M.2 NVMe drive |
| Power Consumption | Not specifically published; engineered for desktop-form-factor efficiency for AI training/inferencing | Up to 1,500 W under heavy load (as specified in the DGX Station A100 hardware datasheet) |
| Software/OS | Runs NVIDIA DGX OS with a full-stack AI software suite (including pre-configured drivers and optimized AI libraries) | Runs NVIDIA DGX OS – pre-configured with the NVIDIA AI Software Stack and containerized deep learning frameworks for streamlined deployment across cloud or local environments |
| Form Factor | Desktop AI supercomputer – purpose-built for on-premises development and rapid prototyping with a “coherent memory” design that minimizes data movement overhead | Desktop workstation-class AI supercomputer – built to deliver data-center-level performance in an office-friendly chassis with defined dimensions and thermal specifications (518 mm D × 256 mm W × 639 mm H; 91 lbs) |
| Additional Features | – Next-generation FP4 accuracy for training and inference via 5th-generation Tensor Cores – Integrated, high-bandwidth coherent memory with NVLink-C2C interconnect | – Proven performance on deep learning and inferencing tasks with established A100 GPUs – Comprehensive connectivity, storage, and environmental controls (operating temperature 10°C–35°C) |
A comparison between the latest NVIDIA Grace Blackwell DGX Station and the 2021 DGX A100 built around Ampere GPUs. Source: IDC, 2025
The DGX Station is equipped with the NVIDIA AI software stack, providing tools and frameworks for developing, training, and deploying AI models. This integration ensures compatibility with cloud and data center infrastructures, enabling scalability and flexibility for AI developers and researchers.
ISV Collaboration and Application Optimization
NVIDIA’s Blackwell architecture introduces significant advancements in computer-aided engineering (CAE) software, enabling simulation tools to achieve up to 50 times faster performance according to NVIDIA. This acceleration is particularly impactful for real-time digital twin applications, which rely on high computational efficiency to model and analyze complex systems dynamically. By integrating Blackwell technologies, NVIDIA announced that leading CAE software providers, including Ansys, Altair, Cadence, Siemens, and Synopsys, have enhanced their capabilities to address challenges in industries such as aerospace, automotive, energy, and manufacturing.
The architecture leverages CUDA-X libraries and optimized blueprints to improve simulation accuracy, reduce development time, and lower costs while maintaining energy efficiency.
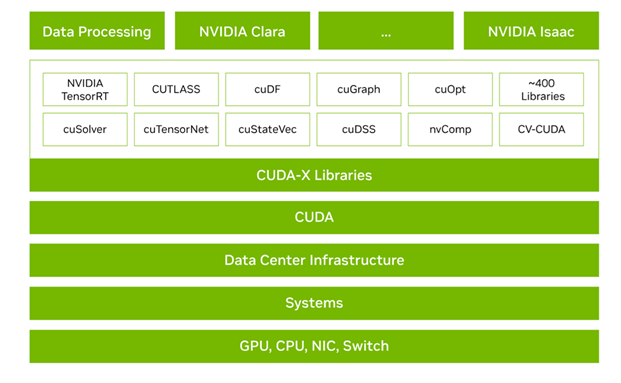
CUDA-X is a comprehensive suite of software libraries and tools designed to accelerate computing across a wide range of applications, including AI, data analytics, and scientific computing. In the context of the DGX Station, CUDA-X plays a pivotal role by optimizing the performance of AI workloads. It provides developers with access to highly efficient libraries for deep learning, such as cuDNN and TensorRT, which are essential for training and inferencing large-scale models. Additionally, CUDA-X enables seamless integration with the DGX Station’s advanced hardware, including the Grace Blackwell Ultra Superchip and NVLink-C2C interconnect, ensuring efficient utilization of the system’s computational and memory resources. This synergy allows researchers and developers to achieve faster model development cycles and enhanced scalability, making the DGX Station a powerful platform for cutting-edge AI innovation.
For example, Cadence has demonstrated the ability to simulate multibillion-cell computational fluid dynamics models on a single NVIDIA GB200 NVL72 server within 24 hours—a task that previously required extensive CPU clusters and multiple days. This breakthrough highlights the potential of Blackwell-powered systems to transform engineering workflows, enabling more efficient design processes and reducing reliance on physical testing methods.
The collaboration between NVIDIA and ISVs underscores the growing importance of accelerated computing in addressing computationally intensive tasks, paving the way for innovations in digital twin technology and beyond.
IDC Opinion
The discontinuation of 32-bit OpenCL and CUDA support in the Blackwell architecture primarily affects legacy applications that haven’t transitioned to 64-bit, while modern, fully 64-bit productivity software remains largely unaffected and continues to benefit from Blackwell’s enhanced performance. For instance, many professional workflow applications, simulation tools, and AI development environments have long since moved to 64-bit, allowing them to take full advantage of new features like advanced Tensor Cores, FP4 precision, and high-bandwidth coherent memory without issue. However, legacy or specialized tools still dependent on 32-bit components might experience errors or fallback CPU processing, which can slow down specific tasks and temporarily impede productivity. In practice, organizations relying on such legacy applications will need to update or recompile their applications to fully harness the substantial benefits offered by the new Blackwell RTX Pro GPUs in workstation scenarios.
NVIDIA’s Blackwell architecture introduces a new generation of Tensor Cores that natively support FP4 arithmetic. But hardware alone isn’t enough to harness the full potential of FP4 precision. NVIDIA has co-developed an optimized software ecosystem built into its DGX systems that fine-tune the quantization and calibration processes for FP4 computations. These algorithmic enhancements ensure that the error margins introduced by reducing precision are minimized. While FP4 precision provides an effective way to significantly boost compute performance and energy efficiency, NVIDIA has to demonstrate those benefits in use cases, compared to formats like FP16 or FP32, especially when marketed heavily with products like the DGX Spark.
Nearly a decade ago, NVIDIA introduced the DGX desktop workstations as an entirely in-house developed AI systems to direct sales. Now, by opening up its latest GB platforms to OEM partners, NVIDIA is strategically broadening its distribution channels and market reach. This shift not only enriches desktop workstation solutions with cutting edge technology across a wider audience but also empowers partners to innovate and adapt NVIDIA’s advanced AI capabilities to diverse industrial needs, reinforcing the company’s leadership and expanding its influence.
The DGX Spark and DGX Station face cost-performance challenges compared to SFF and high-end tower workstations with discrete graphics cards. Students, startups and small software houses, who are key drivers of AI development, may find NVIDIA’s solutions costly and prefer more efficient options like gaming graphics cards.
In conclusion, the introduction of Blackwell architecture and advancements in DGX systems reflect NVIDIA’s commitment to delivering cutting edge solutions for professionals, researchers, and enterprises. As the AI landscape evolves, NVIDIA’s strategic approach to expanding access through OEM partnerships and optimizing performance across software ecosystems ensures that its technology remains at the forefront of AI driven workflows.



